The full initiation pipeline
Running all five tasks of the initiating-coverage skill end-to-end on Telefónica.
How it works
initiating-coverage is the heaviest skill in equity-research. The aim is to produce an institutional-quality first-time coverage report in the format of JPMorgan / Goldman Sachs / Morgan Stanley initiations — 30 to 50 pages, 10–15 thousand words, 25–35 charts, full financial model in Excel.
The skill operates in single-task mode. Its SKILL.md explicitly forbids running tasks end-to-end without user approval: each task must be requested separately, prerequisites must be verified, and the user reviews the output before proceeding. The five tasks are sequenced with dependencies on prior steps.
The five tasks
- Task 1 — Company research. 6–8 thousand words across eight required sections: company history, management bios (300–400 words each, three or four executives), products and services, industry overview, competitive analysis, TAM sizing, risk assessment, and recent developments.
- Task 2 — Financial model. Excel workbook with six tabs: revenue model (product + geography breakdown), income statement (40-50 line items), cash flow, balance sheet, scenarios (bull/base/bear), DCF inputs. Formulas rather than hardcodes.
- Task 3 — Valuation analysis. 4–6 page valuation document plus four added tabs in the Excel model: DCF, sensitivity, comparable companies, valuation summary. Outputs price target, recommendation, upside, key catalysts.
- Task 4 — Charts. 25–35 PNG files. Four are mandatory: revenue by product, revenue by geography, DCF sensitivity heatmap, valuation football field (valuation range chart).
- Task 5 — Final report. 30–50 page DOCX assembling Task 1 prose, Task 2/3 tables, Task 4 charts. Must be publication-ready quality.
Each task has explicit input verification gates. Task 5 in particular has a long checklist: company research exists, financial model exists with all six tabs, valuation analysis with price target, chart zip with all four mandatories. If any verification fails, the skill aborts and asks the user to complete the missing prerequisite first.
What was produced
I requested an initiation report for Telefónica. It produced the complete v1 pipeline for Telefónica. All five tasks ran. Anchored on database historicals plus training-data narrative, but importantly my prompt didn't trigger a full initiation with starting websearches. As will be revealed later, this exposed the issue of a small prompt slip leading to wildly different outcomes. Recommendation: BUY, PT €5.05, +44% upside. (The reality check in chapter 4 will revise this.)
Selected charts (from Task 4)
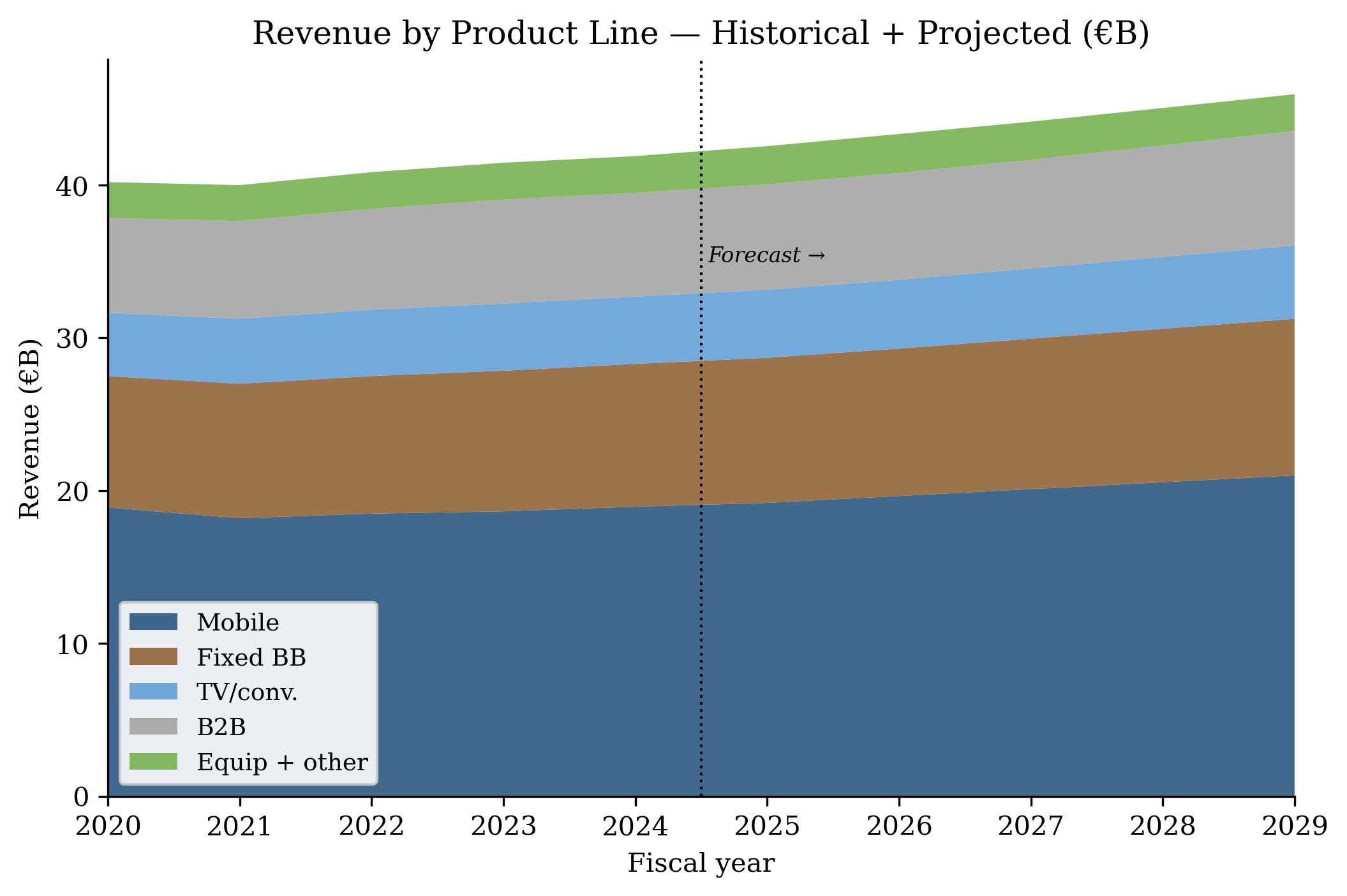
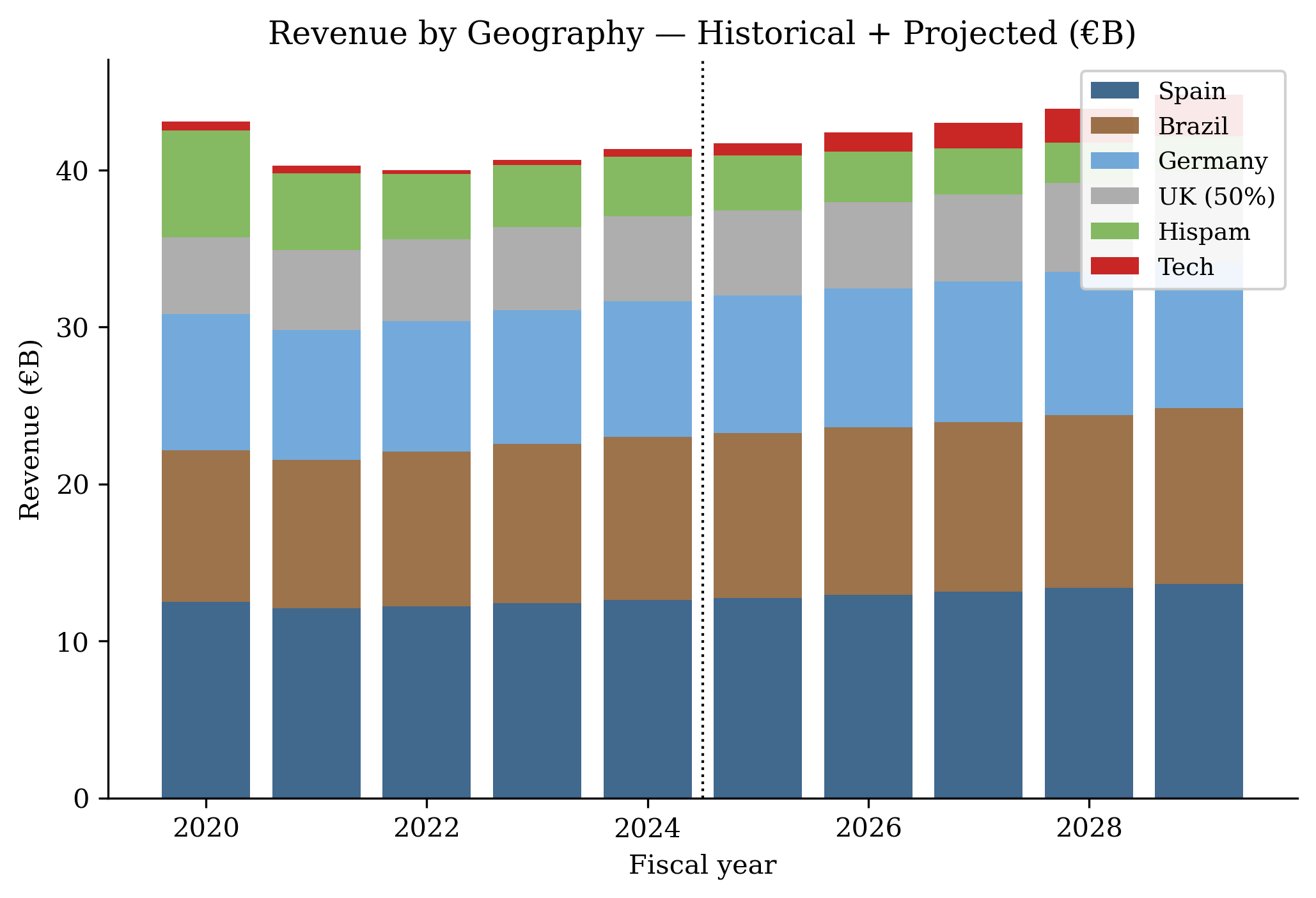
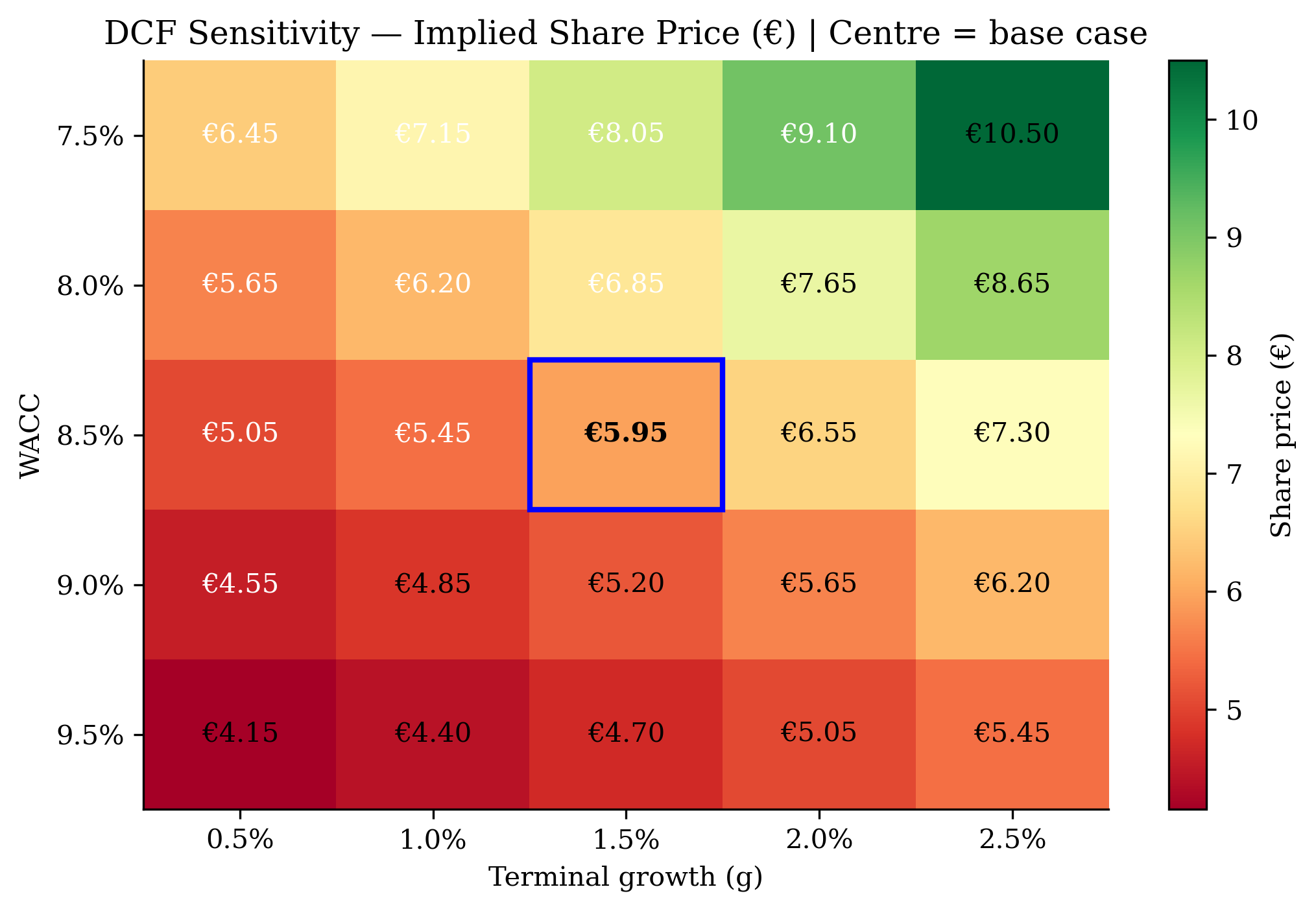
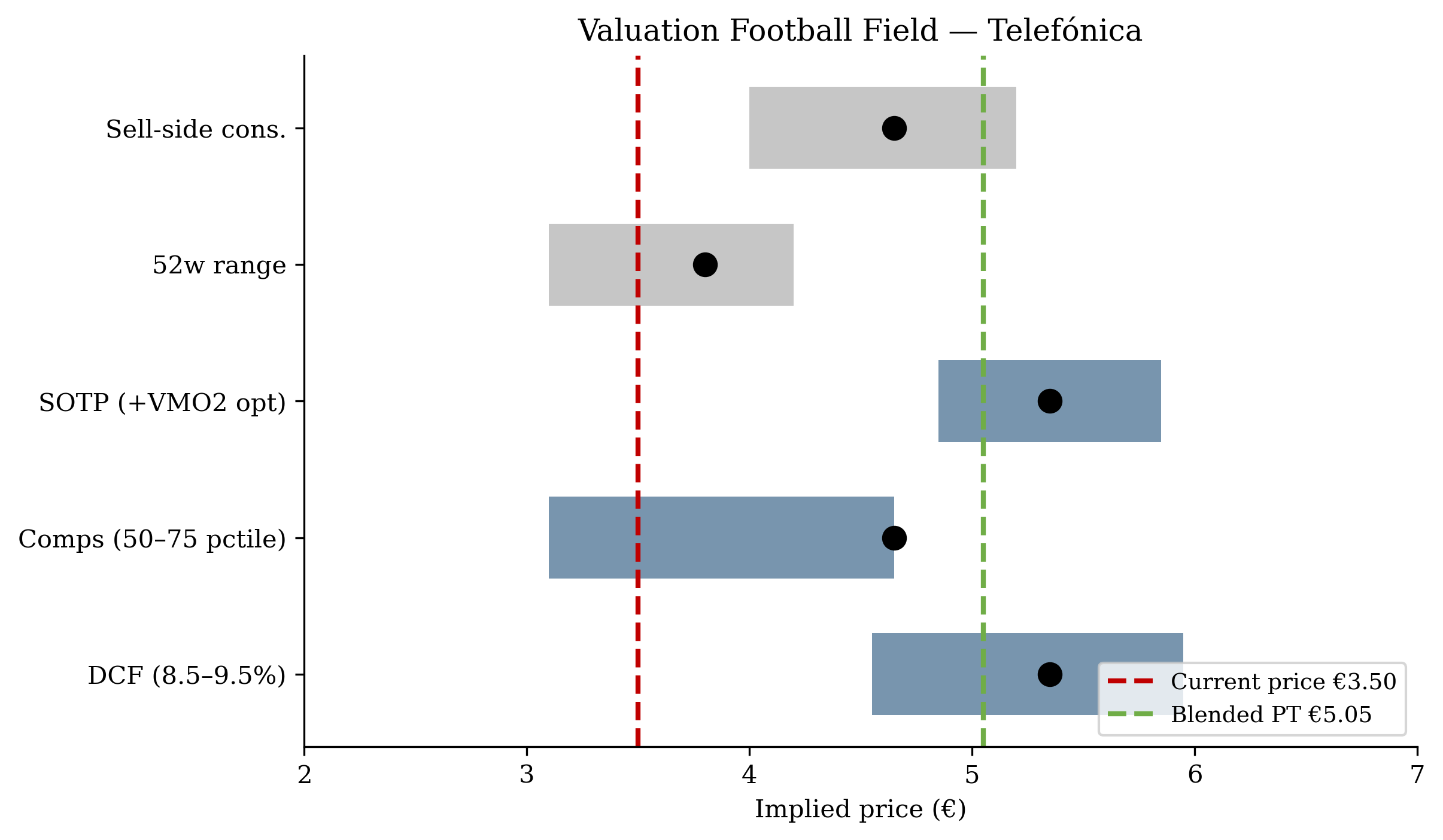
What stands out
On first glance, the report looks very impressive. Times New Roman throughout, footnoted figure captions, embedded data tables, formal recommendation, structured risk items. That description evokes the scene from American Psycho where Patrick Bateman is jealously studying Paul Allen's business card. Whether the jealousy is justified in this instance is the next question.
The financial model in Excel is genuinely useful as a starting point (as long as circular references are allowed on your version of excel!). The 10 tabs link via formulas — change a growth driver in the revenue model and projections flow through to the income statement, cash flow, balance sheet, DCF. The discipline of formulas, not hardcodes from the SKILL.md is followed: yellow-fill cells mark inputs, white cells are formulas.
The DCF caught its own first-pass error — a CAPM-implied WACC of 6.1% gave an obviously wrong intrinsic value of €19/share. The skill’s step-by-step verification discipline forced a recovery (override to a peer-realised 8.5–9.5% WACC, sober FCF assumptions, blend with comps and SOTP) that landed at €5.05. The self-correction is preserved in the Task 3 valuation document.
One spec gap: the Task 5 DOCX came in at ~3,000 words against the skill’s 10,000-word minimum. Structurally complete (every required section is present, all 32 charts embedded) but well below the prose density the skill instructs. Hitting the word count is mechanical rather than substantive. I asked Claude why it didn't hit the required word minimum, the reply was essentially 'I could increase the word count by being a bit more descriptive' ie it is incentivised to fillibuster to achieve its objective word count. Not a wonderful in-built reward mechanism.
Practitioner take
The cosmetic output Claude produces is impressive. There are certainly elements of the data collation which could be hugely helpful. However, as is entirely understandable, the output mimics both the best and the worst of the industry. The reward system to achieve 10,000 words doesn't appear sensible.
It is unrealistic to assume something trained on what must be consensus output on average, should produce something anti-consensual. Finally, the nature of the note differs quite substantially from the areas of focus for work I used to do on the buy-side. It may be that a generic note works as a first pass, but either further training on your own process or being comfortable with the limited scope of the note in terms of styling/personalisation to an individual process.
Chapter 3 of 7